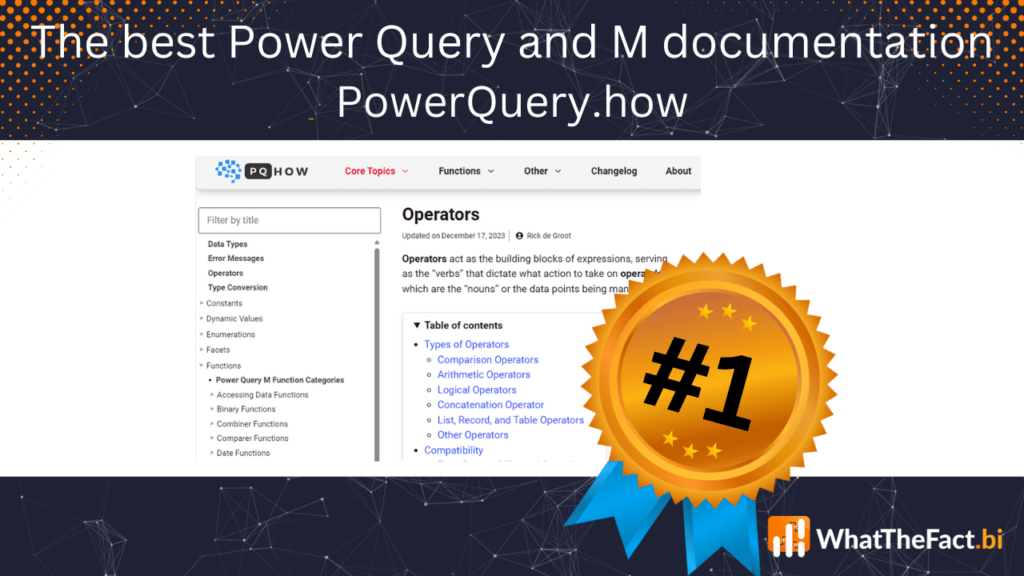
Die beste Power Query und M Dokumentation – PowerQuery.how
March 11, 2024Eine gute Dokumentation ist unerlässlich, um in der IT effizient arbeiten zu können. Manchmal leistet ein Softwarehersteller gute Arbeit und…
Entferne Zeilen, die in einer anderen Tabelle existieren, mit Power Query – Wie man einen Anti-Join (Not-In-Join) zur Datenbereinigung in Power BI verwendet
April 16, 2023Wenn Sie Ihre Daten in Power Query aufbereiten, kann es vorkommen, dass Sie Zeilen in einer Tabelle entfernen müssen, die…
Ersetzung von bedingten Werte in einer Spalte in Power Query in einem Schritt
March 13, 2023Wenn man viel mit Power Query arbeitet, muss man früher oder später Werte in einer Spalte ersetzen, die auf bestimmten…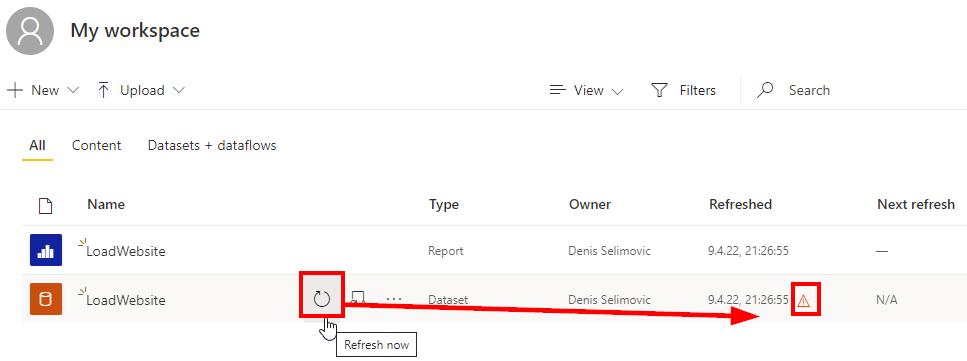
Laden von Websitedaten in Power BI Service ohne Verwendung eines Gateways
April 10, 2022Oftmals erstelle ich in Power BI Desktop einen Bericht mit Daten von einer Website. Angenommen, wir erstellen einen Bericht und…Datenbasis in Power Query gegen veröffentlichtes Power BI Datenset tauschen
June 11, 2021Gelegentlich sieht man als Power BI Entwickler mit der Aufgabe konfrontiert, die Datenbasis bei bestehenden Reports gegen ein veröffentlichtes Power…ISO 8601 Kalenderwoche in Power Query berechnen
January 9, 2021Bereits letzte Woche haben wir uns mit der Thematik der korrekten Berechnung der ISO Kalenderwoche in DAX beschäftigt. Da die…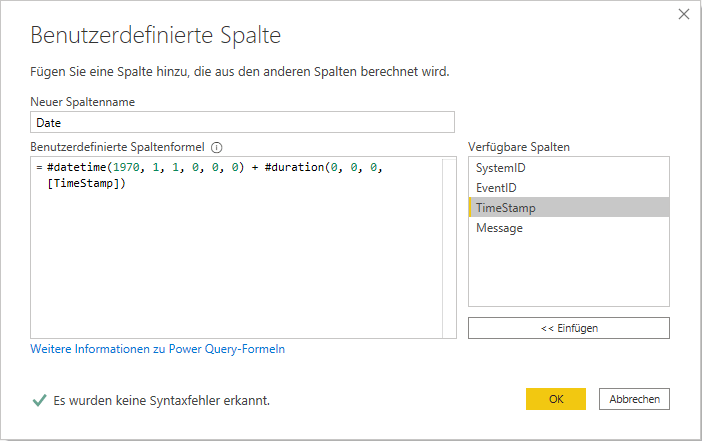
UNIX Timestamp in DATE bzw. DATETIME Format in Power BI umwandeln
November 1, 2020Wer ein Datum bzw. Datetime-Format im UNIX-Format erhält, der wundert sich zuerst, was es damit auf sich hat bzw. wie…Meine häufig verwendeten Power BI Snippets
October 6, 2020In meinem ersten Blog-Post habe ich kurz erwähnt, dass mein digitales Notizbuch - in form von OneNote - gut gefüllt…Mehrere Tabellen kombinieren mit UNION / UNION ALL in SQL Server, APPEND in Power Query oder UNION in DAX
October 2, 2020Wenn man mehrere Tabellen miteinander kombinieren möchte, dann stellt sich die Frage, ob man dies bereits in der Datenquelle wie…Dateien mit ändernden Namen aus Ordnern mit ändernden Namen in Power Query laden
September 28, 2020Was erstmal kompliziert und wenig sinnvoll klingt, ist in der Praxis immer mal wieder anzutreffen. Vor kurzem stellte mich der…